
目次 / Contents
1. はじめに
我々は常に大規模なデータを入手できるわけではありません。
医学の、とくに希少疾患の研究では、対象となる患者数が限られていることがよくあります。
このような状況で、どのように信頼性の高い結論を導き出すことができるでしょうか。
本記事では、小標本(サンプルサイズが小さい場合)のための統計手法についてまとめます。
2. 小標本統計の必要性
2.1 大標本近似の限界
統計学の多くの手法は、中心極限定理に基づく大標本近似を前提としています。
しかしサンプルサイズが小さい場合、この近似は適切ではありません。
例えば2値データ(成功/失敗)の場合、一般的にはパラメータの数の約5倍のイベント数が必要とされています。
この条件を満たさない場合、従来の手法(Wald信頼区間など)は信頼性が低くなる可能性があります。
2.2 小標本での課題
小標本での主な課題は以下の通りです:
- 推定が不安定になる
- 信頼区間の幅が適切でなくなる
- 検出力の低下
- 極端な結果(0%や100%)の処理ができなくなる
これらの課題に対処するため、特別な統計手法が開発されてきました。
3. 小標本のための主要な統計手法
小標本に対処するための主要なアプローチは以下の3つです:
- 変数変換
- 正確な確率計算
- ペナルティ付き尤度
それぞれについて詳しく見ていきましょう。
3.1 変数変換
変数変換は、データの分布を正規分布に近づけることで大標本近似の性能を改善する方法です。
例えば2項分布の場合、以下の対数オッズ変換がよく用いられます:
$$\theta = \log\left(\frac{\pi}{1-\pi}\right)$$
ここで、$π$は成功確率です。
この変換により、推定量の分布が正規分布に近づき、信頼区間の精度が向上します。
3.2 正確な確率計算
正確な確率計算は、近似を用いずに直接確率を計算する方法です。
代表的な手法にClopper-Pearson法があります。
Clopper-Pearson信頼区間
Clopper-Pearson信頼区間は、2項分布のパラメータ $π$ に対する正確な信頼区間を提供します。
下側限界は以下の式を解くことで得られます。
$$\sum_{i=0}^y \binom{N}{i} \pi^i (1-\pi)^{N-i} = \frac{\alpha}{2}$$
上側限界も同様に計算されます。
ここで、$y$は観測された成功回数、$N$は試行回数、$α$は有意水準です。
Clopper-Pearson法は保守的な推定を行うため、実際の信頼水準は名目上の水準よりも高くなる傾向があります。
Mid-p法
Mid-p法は、Clopper-Pearson法の保守性を緩和するための手法です。
観測データが生じる確率の半分を除外することで、より適切な信頼区間を提供します。
Mid-p法による信頼区間の下側限界は以下の式で定義されます。
$$\sum_{i=0}^{y-1} \Pr(Y = i; \pi, N) + \frac{1}{2}\Pr(Y = y; \pi, N) = \frac{\alpha}{2}$$
3.3 ペナルティ付き尤度
ペナルティ付き尤度は、尤度関数にペナルティ項を追加することで推定の安定性を向上させる方法です。
一般的な形式は以下の通りです。
$$pl(\theta) = l(\theta) + \text{penalty}$$
ここで、$l(θ)$は対数尤度関数、$penalty$はペナルティ項です。
Agresti法
Agresti法は、2項分布のパラメータ推定に対して、以下のペナルティを用います。
$$\hat{\pi} = \frac{y + 2}{N + 4}$$
この方法は、極端な結果(0%や100%)に対しても適切な推定を提供します。
Gart and Zweifel(1967)は, 対数オッズ$\theta=\log [\pi /(1-\pi)]$ の推定においていくつかの推定量を検討した結果, $a=b=1 / 2$ というわずかな補正を加えた$\begin{aligned}\widehat{\theta}=\log \left(\frac{y+1 / 2}{N-y+1 / 2}\right), 95 \% \mathrm{CI}=\widehat{\theta} \pm 1.96 \sqrt{\frac{1}{y+1 / 2}+\frac{1}{N-y+1 / 2}}\end{aligned}$を推奨しています。
この推定量と標準誤差は, サンプルサイズが増えると最尤法より真値に速く収束することがわかっています。
a と b の選択に恣意性を感じますが, y=0 または y=N のときにも計算できるという点で魅力的です.
4. 具体例:2値アウトカムの臨床試験
具体例を通じてこれらの手法の適用を見ていきましょう。
4.1 ミシガンECMO試験
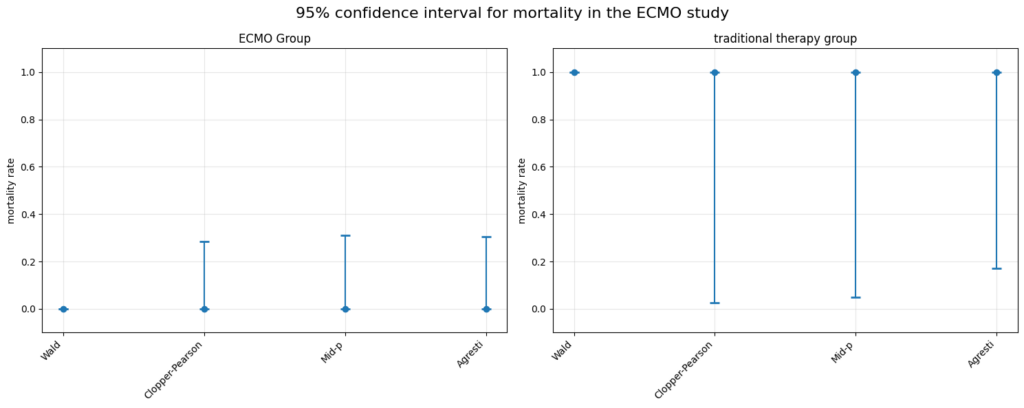
極端な例として、ミシガンECMO試験を考えましょう。
この試験では、ECMO群(11人)の死亡率が0%、従来療法群(1人)の死亡率が100%でした。
このような極端な結果に対して、各手法は以下のような信頼区間を与えます。

import numpy as np
from scipy import stats
from scipy.optimize import brentq
import pandas as pd
import matplotlib.pyplot as plt
# 前述の関数定義(wald_ci, clopper_pearson_ci, mid_p_ci, agresti_ci)はそのまま維持
# データ
ecmo_x, ecmo_n = 0, 11 # ECMOグループ: 11人中0人死亡
control_x, control_n = 1, 1 # 従来療法グループ: 1人中1人死亡
# 信頼区間の計算
methods = ['Wald', 'Clopper-Pearson', 'Mid-p', 'Agresti']
ci_functions = [wald_ci, clopper_pearson_ci, mid_p_ci, agresti_ci]
results = []
for method, func in zip(methods, ci_functions):
ecmo_ci = func(ecmo_x, ecmo_n)
control_ci = func(control_x, control_n)
results.append({
'Method': method,
'ECMO割合': ecmo_x/ecmo_n,
'ECMO下限': ecmo_ci[0] if not np.isnan(ecmo_ci[0]) else 0,
'ECMO上限': ecmo_ci[1] if not np.isnan(ecmo_ci[1]) else 0,
'従来療法割合': control_x/control_n,
'従来療法下限': control_ci[0] if not np.isnan(control_ci[0]) else 1,
'従来療法上限': control_ci[1] if not np.isnan(control_ci[1]) else 1
})
df = pd.DataFrame(results)
# 可視化
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
fig.suptitle('95% confidence interval for mortality in the ECMO study', fontsize=16)
# ECMOグループの可視化
ax1.errorbar(df['Method'], df['ECMO割合'],
yerr=[df['ECMO割合'] - df['ECMO下限'], df['ECMO上限'] - df['ECMO割合']],
fmt='o', capsize=5, capthick=2)
ax1.set_title('ECMO Group')
ax1.set_ylim(-0.1, 1.1)
ax1.set_ylabel('mortality rate')
ax1.grid(True, alpha=0.3)
# 従来療法グループの可視化
ax2.errorbar(df['Method'], df['従来療法割合'],
yerr=[df['従来療法割合'] - df['従来療法下限'], df['従来療法上限'] - df['従来療法割合']],
fmt='o', capsize=5, capthick=2)
ax2.set_title('traditional therapy group')
ax2.set_ylim(-0.1, 1.1)
ax2.set_ylabel('mortality rate')
ax2.grid(True, alpha=0.3)
# x軸ラベルの回転
for ax in [ax1, ax2]:
ax.set_xticklabels(df['Method'], rotation=45, ha='right')
plt.tight_layout()
plt.show()
# 数値結果の表示(前回と同じ)
print(df.to_string(index=False))この結果から、以下のことが分かります:
- Wald法は極端な結果に対して全く機能しません。
- Clopper-Pearson法とMid-p法は、非常に広い信頼区間を与えています。
サンプルサイズが小さいため、真の死亡率について多くのことが言えないことを示しています。 - Agresti法は他の方法よりも狭い信頼区間を与えていますが、それでもかなり広い区間となっています。
5. 小標本統計手法の応用
小標本統計手法は、以下のような分野で特に重要です。
これらの分野では大規模なデータ収集が難しいため、小標本でも信頼性の高い推論を行う必要があります。
- 希少疾患の研究
- 初期段階の臨床試験
- 高コストな実験や観察研究
- 倫理的制約がある研究
5.1 一般化線形モデルへの拡張
小標本の問題は、単純な2値データだけでなく、より複雑なモデルでも発生します。
一般化線形モデル(GLM)の場合、以下のようなアプローチが考えられます:
- ペナルティ付き最尤法(Firth’s method)
- 正確な条件付き推論
- ベイズ推定(事前分布の利用)
例えばロジスティック回帰の場合、Gelman et al. (2008)はCauchy分布を事前分布として用いたベイズ推定を推奨しています。
$$\beta_j \sim \text{Cauchy}(0, 2.5)$$
ここで、$\beta_j$は回帰係数です。
この事前分布は、極端な推定値を抑制しつつ十分な柔軟性を与えます。
6. 小標本統計手法の限界と課題
小標本統計手法は強力なツールですが、以下のような限界や課題があります:
- 計算の複雑さ:正確な方法は計算負荷が高く、大規模なモデルには適用が難しい場合があります。
- 保守性:一部の方法(特にClopper-Pearson法)は過度に保守的になる傾向があります。
- 手法の選択:状況に応じて適切な手法を選択する必要があり、その判断が難しい場合があります。
- 解釈の難しさ:広い信頼区間は解釈が難しく、意思決定に活用しにくい場合があります。
これらの課題には以下のような対処が可能です:
- 計算効率の改善(近似アルゴリズムの開発など)
- 新しいペナルティ項の提案
- シミュレーション研究による手法の比較と選択基準の確立
- ベイズ推定とFrequentist法の融合
7. 結論
小標本統計手法は、限られたデータから最大限の情報を引き出すための重要なツールです。
これらの手法を適切に用いることで、より信頼性の高い推論ができ、研究資源の効率的な利用などができるようになります。
しかし小標本統計手法は万能ではありません。
結果の解釈には慎重さが必要であり、可能な限りサンプルサイズを増やす努力をすることがもっとも重要です。
小標本統計の分野は活発に研究が進められており、新しいアプローチもいくつか提案されています。
7.1 スパース推定とRegularization
高次元データを扱う際に有効なスパース推定の考え方を小標本問題に応用する方法があります。
LASSO(Least Absolute Shrinkage and Selection Operator)やRidge回帰の考え方を小標本の文脈で適用することで、推定の安定性を向上させる試みがあります。
7.2 ベイズ推定と階層モデル
ベイズ推定は、事前情報を自然に組み込める点で小標本問題に適しています。
特に階層モデル(Hierarchical Model)を用いることで、複数の小規模研究のデータを効果的に統合し、より信頼性の高い推論を行うことができます。
7.3 機械学習的なアプローチ
転移学習(Transfer Learning)の考え方を用いて、類似した大規模データセットから得られた知見を小標本の問題に転用する方法などが提案されています。
7.4 ロバスト統計
外れ値や分布の仮定からの逸脱に強いロバスト統計の考え方も小標本問題に応用されています。
サンプルサイズが小さい場合外れ値の影響が大きくなるため、これらの手法が有利になります。


